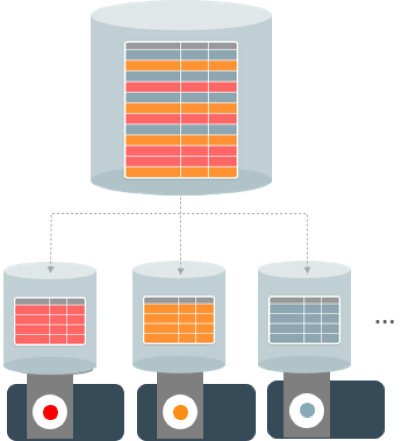
Here is the list of must-attend sessions on Oracle Sharding at the Oracle OpenWorld 2018. Do update your calendars accordingly. Great opportunity to meet with the development team 1:1 to learn more about this technology at the Demo booth.

Please see the details on Sharding conference sessions below:
High Availability and Sharding Deep Dive with Next-Generation Oracle Database [TRN4032]
Wei Hu, Vice President, Oracle
Monday, Oct 22, 9:00 a.m. – 9:45 a.m. | Moscone West – Room 3007
Do you need global availability and scalability? Then the next generation of Oracle Database sharding is for you. In this session learn how to design geo-replicated transaction processing systems for linear scalability with total fault isolation. Whether you want to use commodity shared-nothing hardware or span data centers worldwide, the latest enhancements to existing capabilities for planned maintenance, high availability, disaster recovery, and self-repair enable best-in-class availability for Oracle Databases of any size on any platform.
Industrial-strength Microservice Architectures with Next-Generation Oracle Database [TRN5515]
Dominic Giles, Master Product Manager, Oracle
Wei Hu, Vice President, Oracle
Anil Madan, Oracle
Monday, Oct 22, 3:45 p.m. – 4:30 p.m. | Moscone West – Room 3003
Microservice Architectures is a very exciting way to develop modern applications. As with any advance, this architecture can impose significant availability and scalability demands on the underlying infrastructure. This session reviews the challenges and shows how Oracle Database features such as multi-tenant, sharding, and the asynchonous messaging capabilities provided by Oracle Database Advanced Queuing, can simplify the development and operation of industrial-strength microservice architectures. This session will also include real-life examples to illustrate how large scale microservice-based applications are constructed.
Oracle Sharding: Geo-Distributed, Scalable, Multimodel Cloud-Native DBMS [PRO4037]
Mark Dilman, Director, Software Development, Oracle
Srinagesh Battula, Sr. Principal Product Manager, Oracle
Gairik Chakraborty, Senior Director, Database Administration, Epsilon
Tuesday, Oct 23, 12:30 p.m. – 1:15 p.m. | Moscone West – Room 3007
Oracle Database with Oracle Sharding is a globally distributed multimodel (relational and document) cloud-native (and on-premises) DBMS. It is built on shared-nothing architecture in which data is horizontally partitioned across databases that share no hardware or software. It provides linear scalability, fault isolation, and geographic data distribution for shard-amenable applications. Oracle Sharding does all this while rendering the strong consistency, full power of SQL and the Oracle Database ecosystem. Attend this session to learn how you can deploy a sharded database and elastically scale your transactions, database capacity, and concurrent users. The session covers Oracle Sharding 18c features such as user-defined sharding, RAC sharding, Oracle Multitenant support, and more.
Data and Application Modeling in the Brave New World of Oracle Sharding [BUS1845]
John Kanagaraj, Sr. Member of Technical Staff, Architecture, PayPal Inc.
Tuesday, Oct 23, 3:45 p.m. – 4:30 p.m. | Moscone West – Room 3007
The newly introduced Oracle Sharding feature promises horizontal scalability and higher availability for relational applications. However, success or failure in designing and running a sharded application depends on understanding sharding principles and adapting the application to use the right data model. Based on considerable shared experiences with designing, developing, and maintaining sharded applications, this session explores how to qualify and design applications that use the new Oracle Sharding feature.
Oracle Maximum Availability Architecture: Best Practices for Oracle Database 18c [TIP4028]
Lawrence To, Senior Director, MAA Best Practices (Database On-Premise, Exadata, Recovery Appliance and Cloud Database), Oracle
Michael Smith, Consulting Member of Technical Staff, Oracle
Thursday, Oct 25, 11:00 a.m. – 11:45 a.m. | Moscone South – Room 3007
Join Oracle development for the latest updates on high availability best practices in this well-established and heavily attended technical deep-dive session. Learn how to optimize all aspects of Oracle Data Guard 18c. See how to use session draining, application continuity, Oracle Database In-Memory with Oracle RAC, and Oracle GoldenGate with Oracle Data Guard to mask outages and planned maintenance from users and to accelerate time to repair. Hear about the latest high availability best practices with Oracle Multitenant and understand how the new sharded architecture for OLTP applications can achieve even higher levels of high availability and fault isolation. Find out how everything you know about Oracle Maximum Availability Architecture on-premises can be deployed in the cloud.
Using Oracle Sharding on Oracle Cloud Infrastructure [CAS5896]
Charles Baker, Senior Director of Product Management and Strategy, Oracle
Velimir Radanovic, Architect, Oracle
Thursday, Oct 25, 1:00 p.m. – 1:45 p.m. | Moscone South – Room 160
Oracle Sharding offers unlimited scalability, fault isolation, and geographic distribution for web applications. Deployed on the Oracle Cloud, Oracle Sharding provides a cost-efficient way to build high-performance and low-latency applications for OLTP, IoT, DNS analytics; machine learning; and more. Come to this session to learn about how to deploy a sharded database on Oracle Cloud, migrate from a nonsharded to a sharded database, do high-speed data ingestion into the sharded database, deploy microservices using sharding and multitenant features, and much more.
Have a great OOW. We look forward to seeing you there.